Disaster Response

There are three major sections to the parts project. These parts include: an ETL pipeline, a ML pipeline, and a web application that demonstrates the model's efficacy in real time using the user's input. The pipelines used Python libraries Pandas, Numpy, scikit-learn, nltk, and SQLAlchemy. The front-end utilized Flask and plotly.js.
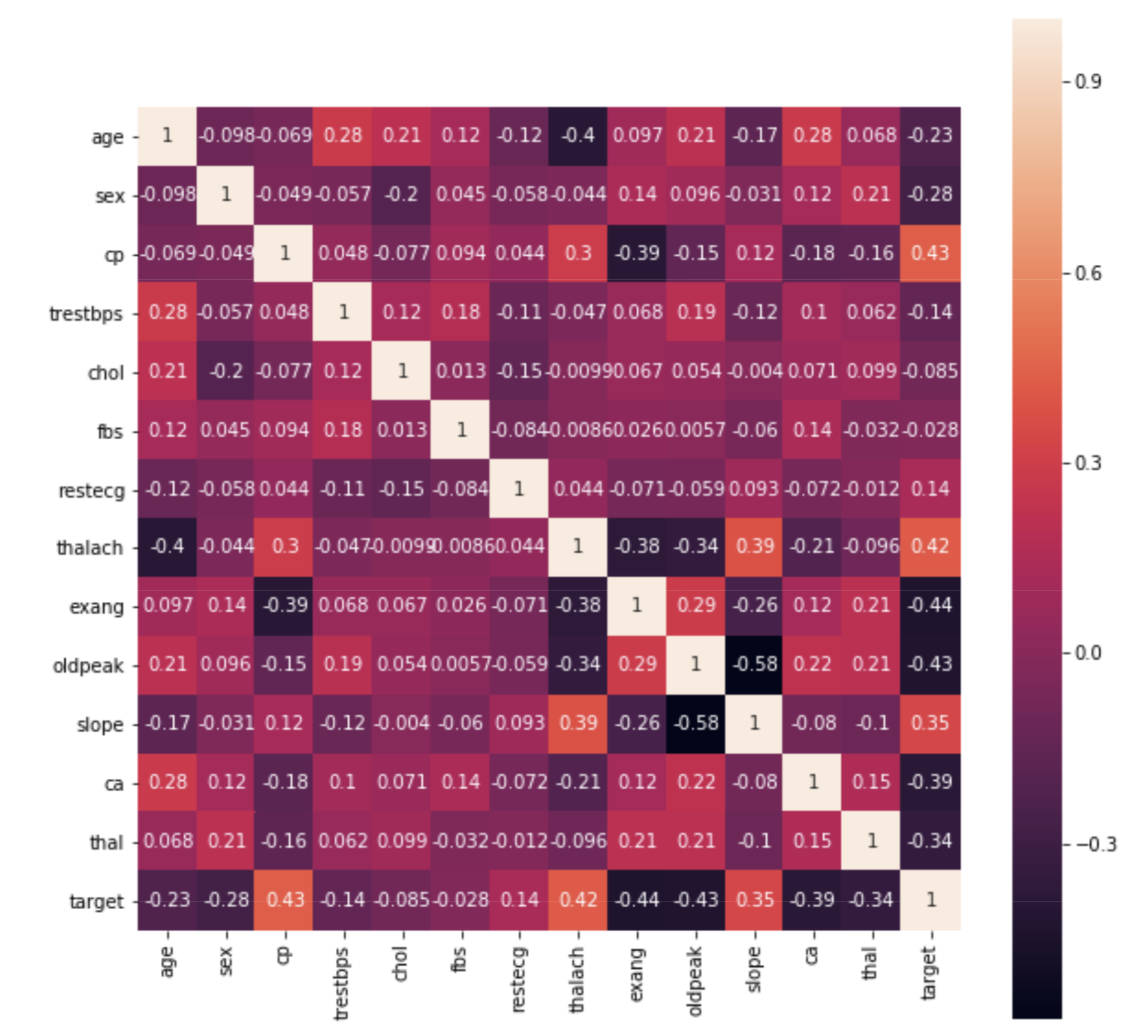
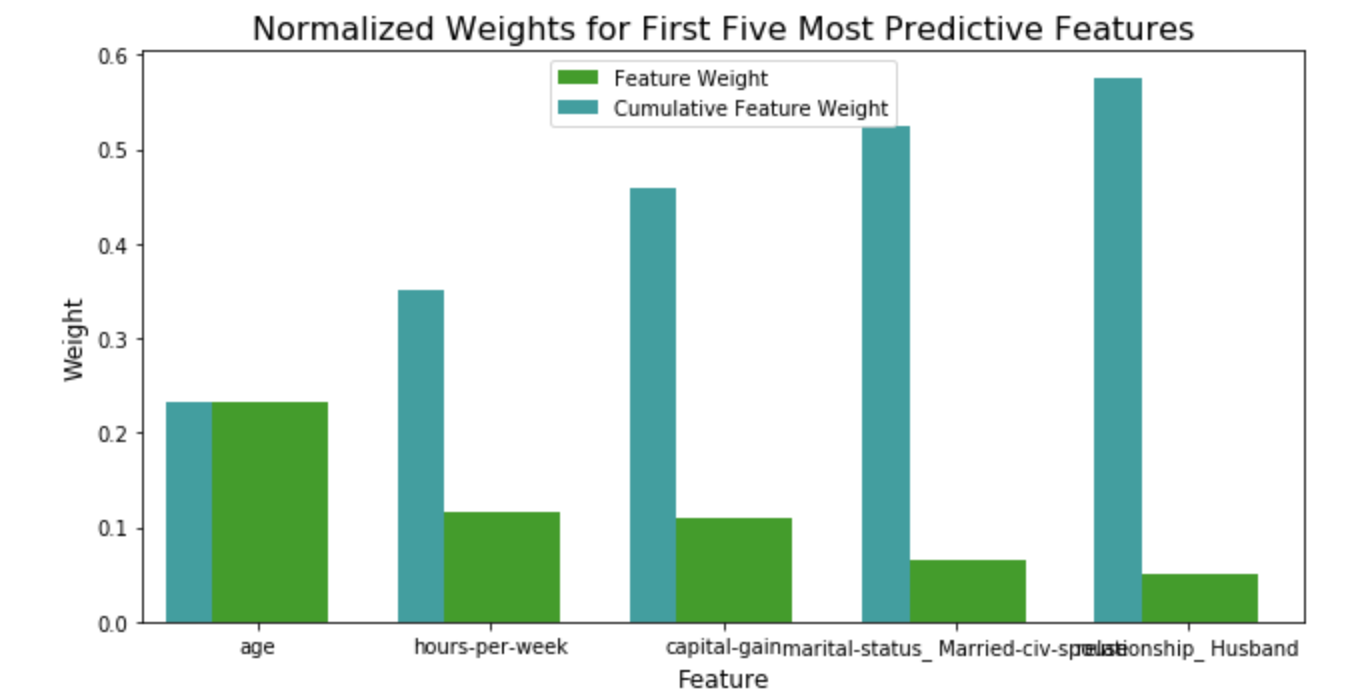
Predicting Heart Disease
Generated a predictive model for heart disease using labeled data. The data were analyzed, visualized, and modeled using Python libraries Pandas, Seaborn, and scikit-learn. The findings were summarized in a Medium blog.

2019 World Series Prediction
Implemented a ML model on data to predict outcome of the 2019 World Series. Back-end completed with Python libraries pandas, NumPy, and scikit-learn.